pandasにおける複数列の組み合わせのカウント
実装内容、結果のみ知りたい方は 2.5 結論 までお進み下さい
第一章 序章
1.1 はじめに
近年,機械学習やDeepLearning等のAIの分野の発展に伴ってプログラミング言語の中でもPythonの人気や需要は高まっている.
その中でもPythonのライブラリであるpandasはAI等の学習における説明変数の整形やビックデータ等のデータ分析などで多々使われるデータ分析ライブラリである.
しかし,実際にライブラリのAPIを隈なく理解している人はあまり多くないのが現状であり,なぜならそのライブラリを使用する頻度が人によって疎らで,たとえ知っていたとしてもその人が記事にするとは限らないからである.そのため,pandasに限らずありがちなケースとしてライブラリを使用したいがそのライブラリのAPI Referenceのサイトからいちいち英語を読みながら自分の使いたい機能を探す時間がないことから,日本語で書かれたQiita等の記事から引用して上手く応用させるケースが挙げられる.
その結果として,数少ない記事が仮に嘘であってもその嘘に気づくことなく皆が記事の内容を参考にしてなんも疑いを持つことなく読み進めてしまうのである.
そこで,筆者が経験したことの中から"pandasにおける複数列の組み合わせのカウント"について取り扱い,既存の記事等と見比べ,比較,検証した結果を提示することでどの方法が優れているかの証明を行い,少しでも参考になればと思い記事にした.
1.2 目的
Pythonでビックデータ等を扱う際,pandasというライブラリを用いることでデータ分析を簡単に行うことが可能だ.しかし,ソースコードの如何によってはメモリ使用量を多く消費したり,処理速度が非常に遅くなってしまうケースが存在する.そのため処理速度を速くしたり,メモリ使用量を少なくしようと改善することはソースコードを書いている人にとってはそのソースコードの目的が何であれ共通の課題となりうる.その結果として,わからないこと等が出てきた際には調べるのが定石だが,調べていても自分の知りたいことが記事にされている保証はどこにもないのである.
今回筆者が題材にした”pandasにおける複数列の組み合わせのカウント”において調べたところ,これに該当する日本語の記事が少ししか見つけることができず,また多くの記事では
pandasにおける単数列のカウウトにおいては,
pd.Series.value_counts()を用いる.
しかし,複数列の組み合わせのカウントでは,value_counts()を用いることができない.
と書かれており,apply()やリスト内表記等々の方法を用いて複数列の組み合わせのカウント行っていた.しかし,実際はpd.DataFrame.value_counts()が存在するためvalue_counts()を用いて処理を行うことは可能であり,value_counts()が使えないという表現は偽りなのである.
そこで”pandasにおける複数列の組み合わせのカウント”の記事で記されていたソースコードとpd.DataFrame.value_counts()を行うソースコードをメモリ使用量と処理速度の観点から複数のデータを用いて比較し,筆者が提案するソースコードの方が良いと考えられた場合,この記事と通してそのソースコードを勧めることで同じような内容で困っている方がこの記事を見つけて少しでも役に立つことが目的である.
実際に”pandasにおける複数列の組み合わせのカウント”について他のサイトの記事内で書かれていたソースコードを2つ以下に示す.
import pandas as pd # sample data df = pd.DataFrame({"A":[1,2,3,1,2,3], "B": ["B1","B2", "B2","B1","B2","B2"], "C":["C1", "C1", "C1", "C1", "C1", "C2"]}) # counting cols = ["A", "B", "C"] ser = df[cols].astype(str)\ .apply(lambda lis: [ x for x in lis], axis=1)\ .str.join(" | ")\ .value_counts()
import pandas as pd # sample data df = pd.DataFrame({"A":[1,2,3,1,2,3], "B": ["B1","B2", "B2","B1","B2","B2"], "C":["C1", "C1", "C1", "C1", "C1", "C2"]}) # counting freq = df.groupby(['A', 'B','C']).size().reset_index()
1つめのコードではデータを作成した後にカウントを行うカラムを指定し,データの指定したカラムのキャストを行って要素の型を文字列にした.その後にlambda関数とリスト内表記,またstr.joinの処理を続けて行うことでカウントを行うカラムに対してpd.Series.value_counts()を施せるようになるため,最後にvalue_counts()をして複数列の組み合わせのカウントを実現している.
一方2つ目のコードではgroupbyでカラムを指定してあげることでグループ化を行い,その上でsize()を加えることで複数列の組み合わせのカウントを実現している.また,最後にreset_index()を処理として加えることで最終的なデータの型をpd.DataFrameになるようにした.
第二章 本論
2.1 目的
今回の目的は”pandasにおける複数列の組み合わせのカウント”と検索した際に見られるソースコード
import pandas as pd # sample data df = pd.DataFrame({"A":[1,2,3,1,2,3], "B": ["B1","B2", "B2","B1","B2","B2"], "C":["C1", "C1", "C1", "C1", "C1", "C2"]}) # counting cols = ["A", "B", "C"] ser = df[cols].astype(str)\ .apply(lambda lis: [ x for x in lis], axis=1)\ .str.join(" | ")\ .value_counts()
import pandas as pd # sample data df = pd.DataFrame({"A":[1,2,3,1,2,3], "B": ["B1","B2", "B2","B1","B2","B2"], "C":["C1", "C1", "C1", "C1", "C1", "C2"]}) # counting freq = df.groupby(['A', 'B','C']).size().reset_index()
と筆者が提案するソースコード
import pandas as pd # sample data df = pd.DataFrame({"A":[1,2,3,1,2,3], "B": ["B1","B2", "B2","B1","B2","B2"], "C":["C1", "C1", "C1", "C1", "C1", "C2"]}) # counting tmp_df = df.value_counts().reset_index()
との処理速度,メモリ使用量の検証の観点から分散分析,t検定を行って比較を行う.また,それに応じた各ソースコードのメリットデメリットについて考察することを目的とする.
筆者の提案するソースコードでは他のソースコードと同様に複数列の組み合わせのカウントを行ったのちに何らかの処理を行うことを前提にしているので複数列の組み合わせのカウントを表示するだけではなく元のデータの型,つまりpd.DataFrameに戻すところまでを実現させた.そのため,用意したデータに対してvalue_counts()を行い,ここまでの処理だとpd.Series型が返ってくるのでreset_index()によってカウント以外のカラムがDataFrameのindexになってしまうのをカラムに戻すことでDataFrameで返すことを実現させている.
処理後のデータの型はpd.Series.value_counts()のコードがpd.Series,groupby().size()のコードがpd.DataFrame,pd.DataFrame.value_counts()のコードがpd.DataFrameとなっている.
2.2 方法
実験の実行環境は以下の通りである。
2.3 結果
2.3.0 準備
用いるDataframe型のデータを
repeat_time = 100 # 繰り返す回数 dataframe_len = 10000 # Dataframeのindexの長さ for i in range(repeat_time): random.seed(i) group_list = [random.randint(0, 60) for j in range(dataframe_len)] random.seed(i+2) value_list = [random.randint(0, 100) for j in range(dataframe_len)] sample_df = pd.DataFrame({'group': group_list, 'value': value_list})
ランダムな整数を0から100の範囲で生成させたものをデータにした.
目安として,データのindexが10000に対してgroup_listを0から60の整数,value_listを0から100の整数にすることでおおよそ固有の複数列の組み合わせが半分の5000になるようにしている.
2.3.1 処理速度の検証結果
処理速度の観点において以下のpd.Series.value_counts()を用いた複数列の組み合わせのカウントを行うソースコードを実行させた.
処理速度の比較方法として2×10000のDataFrameに対して処理を100回繰り返し,10の倍数目の処理速度,累計処理速度の平均を算出することで比較する.
# pd.Series.value_counts() import pandas as pd import time import random from statistics import mean, median,variance,stdev def counting_multiple_dataframe(df): # 比較するソースコード cols = ["group", "value"] ser = df[cols].astype(str)\ .apply(lambda lis: [ x for x in lis], axis=1)\ .str.join(" | ")\ .value_counts() if __name__ == '__main__': repeat_time = 100 # 繰り返す回数 cum_execute_time = 0 # 累計処理時間 dataframe_len = 10000 # Dataframeのindexの長さ データサイズ execute_time = [] # 処理時間リスト for i in range(repeat_time): # データ作成 random.seed(i) group_list = [random.randint(0, 60) for j in range(dataframe_len)] random.seed(i+2) value_list = [random.randint(0, 100) for j in range(dataframe_len)] sample_df = pd.DataFrame({'group': group_list, 'value': value_list}) start = time.time() # 処理開始時間 counting_multiple_dataframe(sample_df) # 複数列の組み合わせのカウント end = time.time() # 処理終了時間 execute_time.append(end - start) # 1回の処理時間計算 if(i % 10 == 0): print('one time runtime(', i, '):', execute_time[i]) # 10*i回の処理時間表示 print('平均:{0:.5f} [sec]'.format(mean(execute_time))) # 100回の処理時間の平均表示 print('分散:{0:.8f} [sec]'.format(variance(execute_time))) # 分散 print('標準偏差:{0:.8f} [sec]'.format(stdev(execute_time))) # 標準偏差
上記の複数列の組み合わせのカウントを行うソースコードの実行結果は以下の通りであった.
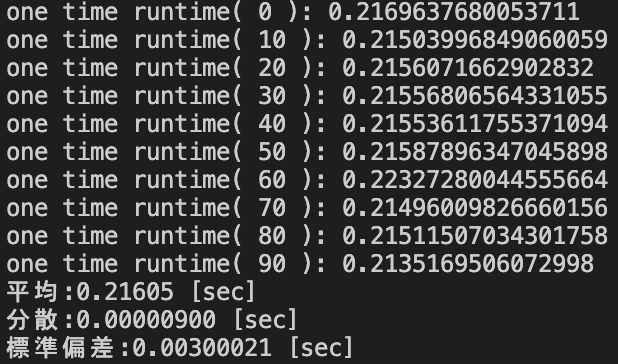
一方同じ観点において,以下のgroupby().size()を用いた複数列の組み合わせのカウントを行うソースコードを実行させた.
# groupby().size() import pandas as pd import time import random from statistics import mean, median,variance,stdev def counting_multiple_dataframe(df): # 比較するソースコード freq = df.groupby(['group','value']).size().reset_index() if __name__ == '__main__': repeat_time = 100 # 繰り返す回数 cum_execute_time = 0 # 累計処理時間 dataframe_len = 10000 # Dataframeのindexの長さ データサイズ execute_time = [] # 処理時間リスト for i in range(repeat_time): # データ作成 random.seed(i) group_list = [random.randint(0, 60) for j in range(dataframe_len)] random.seed(i+2) value_list = [random.randint(0, 100) for j in range(dataframe_len)] sample_df = pd.DataFrame({'group': group_list, 'value': value_list}) start = time.time() # 処理開始時間 counting_multiple_dataframe(sample_df) # 複数列の組み合わせのカウント end = time.time() # 処理終了時間 execute_time.append(end - start) # 1回の処理時間計算 if(i % 10 == 0): print('one time runtime(', i, '):', execute_time[i]) # 10*i回の処理時間表示 print('平均:{0:.5f} [sec]'.format(mean(execute_time))) # 100回の処理時間の平均表示 print('分散:{0:.8f} [sec]'.format(variance(execute_time))) # 分散 print('標準偏差:{0:.8f} [sec]'.format(stdev(execute_time))) # 標準偏差
上記のデータの複数列の組み合わせのカウントを行うソースコードの実行結果は以下の通りであった.
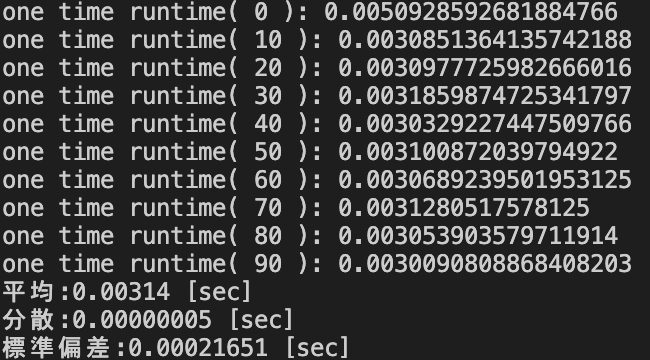
さらに同じ観点において,以下の筆者の提案するpd.DataFrame.value_counts()を用いた複数列の組み合わせのカウントを行うソースコードを実行させた.
# df.value_counts().reset_index() import pandas as pd import time import random from statistics import mean, median,variance,stdev def counting_multiple_dataframe(df): # 比較するソースコード tmp_df = df.value_counts().reset_index() if __name__ == '__main__': repeat_time = 100 # 繰り返す回数 cum_execute_time = 0 # 累計処理時間 dataframe_len = 10000 # Dataframeのindexの長さ データサイズ execute_time = [] # 処理時間リスト for i in range(repeat_time): # データ作成 random.seed(i) group_list = [random.randint(0, 60) for j in range(dataframe_len)] random.seed(i+2) value_list = [random.randint(0, 100) for j in range(dataframe_len)] sample_df = pd.DataFrame({'group': group_list, 'value': value_list}) start = time.time() # 処理開始時間 counting_multiple_dataframe(sample_df) # 複数列の組み合わせのカウント end = time.time() # 処理終了時間 execute_time.append(end - start) # 1回の処理時間計算 if(i % 10 == 0): print('one time runtime(', i, '):', execute_time) # 10*i回の処理時間表示 print('平均:{0:.5f} [sec]'.format(mean(execute_time))) # 100回の処理時間の平均表示 print('分散:{0:.8f} [sec]'.format(variance(execute_time))) # 分散 print('標準偏差:{0:.8f} [sec]'.format(stdev(execute_time))) # 標準偏差
上記のデータの複数列の組み合わせのカウントを行うソースコードの実行結果は以下の通りであった.
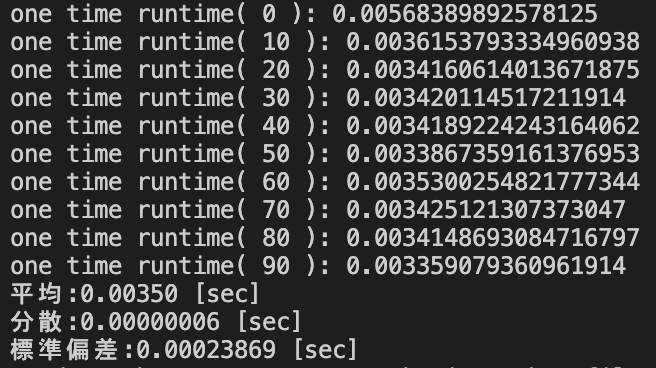
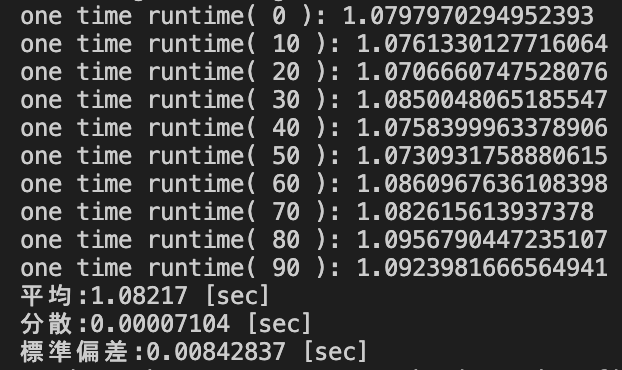
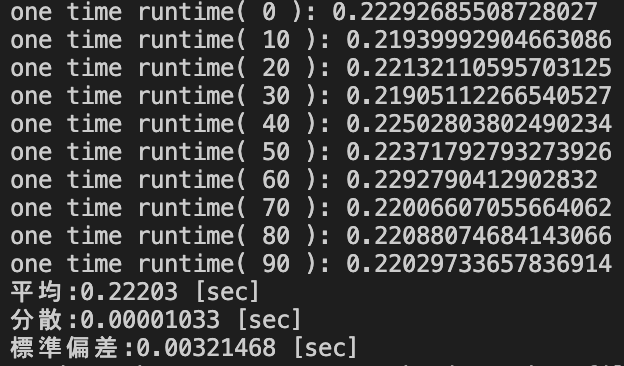
また,上記の検証で用いた2×10000ではなくデータサイズによって処理速度が変化すると考えられることから,データサイズを2×1000,2×50000,3×10000に変更して実行した際の実行結果を以下に示す.
pd.Series.value_counts()を用いたソースコード(2×1000,2×50000,3×10000)
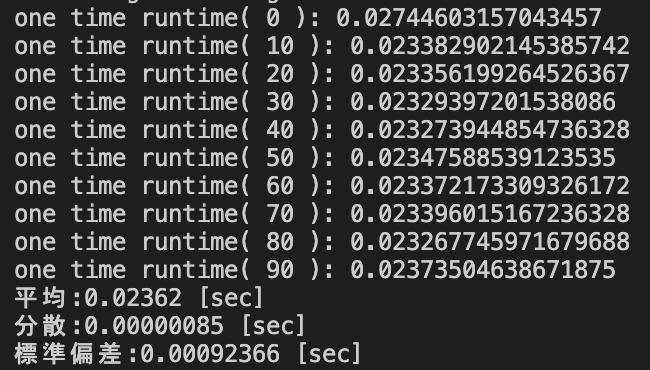
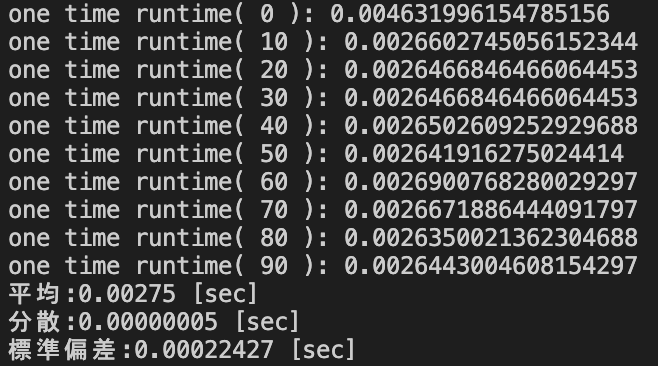
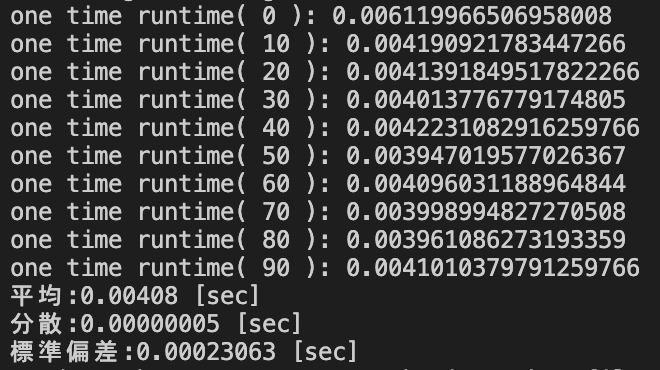
groupby().size()を用いたソースコード(2×1000,2×50000,3×10000)
pd.DataFrame.value_counts()を用いたソースコード(2×1000,2×50000,3×10000)
2.3.1検証結果総括
2.3.1の各コードをfor文で100回繰り返して実行し,そこで計測した処理時間の統計量を計算した.
その計算結果の表を以下に示す.
データサイズ2×10000における処理時間の統計量
| 平均 | 分散 | 標準偏差 | |
|---|---|---|---|
| pd.Series.value_counts() [sec] | 0.21605 | 0.00000900 | 0.0030021 |
| groupby().size() [sec] | 0.00314 | 0.00000005 | 0.00021651 |
| pd.DataFrame.value_counts() [sec] | 0.00350 | 0.00000006 | 0.00023869 |
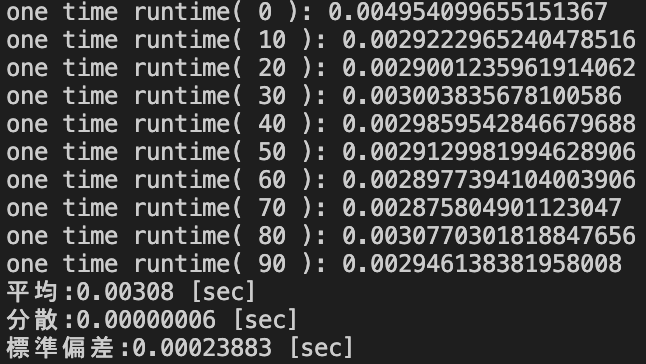
データサイズ2×1000における処理時間の統計量
| 平均 | 分散 | 標準偏差 | |
|---|---|---|---|
| pd.Series.value_counts() [sec] | 0.02362 | 0.00000085 | 0.00092366 |
| groupby().size() [sec] | 0.00275 | 0.00000005 | 0.00022427 |
| pd.DataFrame.value_counts() [sec] | 0.00308 | 0.00000006 | 0.00023883 |
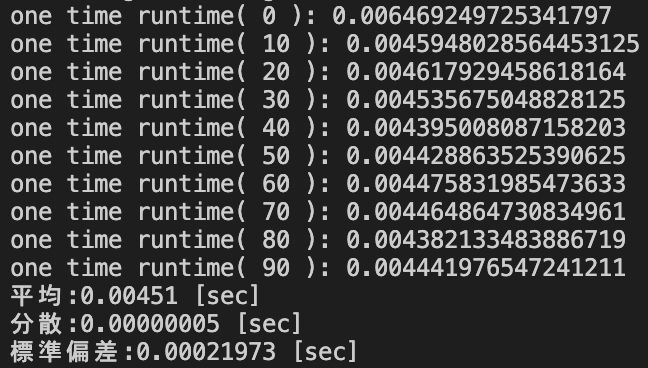
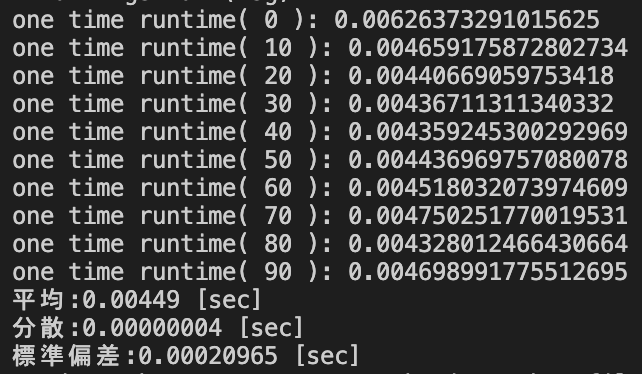
データサイズ2×5000における処理時間の統計量
| 平均 | 分散 | 標準偏差 | |
|---|---|---|---|
| pd.Series.value_counts() [sec] | 1.08217 | 0.00007104 | 0.00842873 |
| groupby().size() [sec] | 0.00408 | 0.00000005 | 0.00023063 |
| pd.DataFrame.value_counts() [sec] | 0.00449 | 0.00000004 | 0.00020965 |
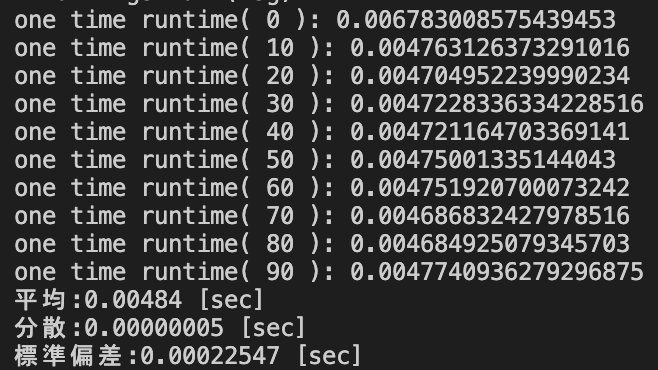
データサイズ3×10000における処理時間の統計量
| 平均 | 分散 | 標準偏差 | |
|---|---|---|---|
| pd.Series.value_counts() [sec] | 0.22203 | 0.00001033 | 0.00321468 |
| groupby().size() [sec] | 0.00451 | 0.00000005 | 0.00021973 |
| pd.DataFrame.value_counts() [sec] | 0.00484 | 0.00000005 | 0.00022547 |
2.3.2 メモリ使用量の検証結果
また,メモリ使用量の観点において以下の複数列の組み合わせのカウントを行うソースコードを実行させた.
# pd.Series.value_counts() import pandas as pd import random from memory_profiler import profile @profile def counting_multiple_dataframe(df): # 比較するソースコード cols = ["group", "value"] ser = df[cols].astype(str)\ .apply(lambda lis: [ x for x in lis], axis=1)\ .str.join(" | ")\ .value_counts() if __name__ == '__main__': dataframe_len = 10000 # Dataframeのindexの長さ データサイズ # データ作成 random.seed(0) group_list = [random.randint(0, 60) for j in range(dataframe_len)] random.seed(1) value_list = [random.randint(0, 100) for j in range(dataframe_len)] sample_df = pd.DataFrame({'group': group_list, 'value': value_list}) counting_multiple_dataframe(sample_df) # 複数列の組み合わせのカウント
上記の複数列の組み合わせのカウントを行うソースコードの実行結果は以下の通りであった.

一方同じ観点において,以下のgroupby().size()を用いた複数列の組み合わせのカウントを行うソースコードを実行させた.
# groupby().size() import pandas as pd import random from memory_profiler import profile @profile def counting_multiple_dataframe(df): # 比較するソースコード freq = df.groupby(['group','value']).size().reset_index() if __name__ == '__main__': dataframe_len = 10000 # Dataframeのindexの長さ データサイズ # データ作成 random.seed(0) group_list = [random.randint(0, 60) for j in range(dataframe_len)] random.seed(1) value_list = [random.randint(0, 100) for j in range(dataframe_len)] sample_df = pd.DataFrame({'group': group_list, 'value': value_list}) counting_multiple_dataframe(sample_df) # 複数列の組み合わせのカウント
上記の複数列の組み合わせのカウントを行うソースコードの実行結果は以下の通りであった.

さらに同じ観点において,以下の筆者の提案するpd.DataFrame.value_counts()を用いた複数列の組み合わせのカウントを行うソースコードを実行させた.
# df.value_counts().reset_index() import pandas as pd import random from memory_profiler import profile @profile def counting_multiple_dataframe(df): # 比較するソースコード tmp_df = df.value_counts().reset_index() if __name__ == '__main__': dataframe_len = 10000 # Dataframeのindexの長さ データサイズ random.seed(0) group_list = [random.randint(0, 60) for j in range(dataframe_len)] random.seed(1) value_list = [random.randint(0, 100) for j in range(dataframe_len)] sample_df = pd.DataFrame({'group': group_list, 'value': value_list}) counting_multiple_dataframe(sample_df)
上記のデータの複数列の組み合わせのカウントを行うソースコードの実行結果は以下の通りであった.

また,上記の検証で用いた2×10000ではなくデータサイズによってメモリ使用量が変化すると考えられることから,データサイズを2×50000,3×10000に変更して実行した際の実行結果を以下に示す.
pd.Series.value_counts()を用いたソースコード(2×50000,3×10000)


groupby().size()を用いたソースコード(2×50000,3×10000)


pd.DataFrame.value_counts()を用いたソースコード(2×50000,3×10000)


2.3.2検証結果総括
2.3.2の各コードを10回実行し,そこで計測したメモリ使用量の統計量を計算した.
その計算結果の表を以下に示す.
データサイズ2×10000におけるメモリ使用量の統計量
| 平均 | 分散 | 標準偏差 | |
|---|---|---|---|
| pd.Series.value_counts() [MiB] | 4.34 | 0.09600 | 0.30984 |
| groupby().size() [MiB] | 0.86 | 0.02933 | 0.17127 |
| pd.DataFrame.value_counts() [MiB] | 0.94 | 0.05378 | 0.23190 |
データサイズ2×50000におけるメモリ使用量の統計量
| 平均 | 分散 | 標準偏差 | |
|---|---|---|---|
| pd.Series.value_counts() [MiB] | 21.31 | 0.62544 | 0.0.79085 |
| groupby().size() [MiB] | 3.6 | 1.30444 | 1.14212 |
| pd.DataFrame.value_counts() [MiB] | 3.43 | 0.71344 | 0.84466 |
データサイズ3×10000におけるメモリ使用量の統計量
| 平均 | 分散 | 標準偏差 | |
|---|---|---|---|
| pd.Series.value_counts() [MiB] | 4.97 | 0.28678 | 0.53552 |
| groupby().size() [MiB] | 1.21 | 0.05211 | 0.22828 |
| pd.DataFrame.value_counts() [MiB] | 1.15 | 0.16944 | 0.41164 |
2.4 考察
2.4.1 2.3.1の検証結果の考察
2.3.1の検証結果から2×10000のデータに対して連続値のカウントを行うソースコードの処理速度を代表値として分散分析,t検定を行うことで各ソースコードの比較,考察を行った.
まず,初めに3つのソースコードの処理速度に差があるかを確認するため分散分析を行った.帰無仮説と対立仮説は以下の通りである.
次に各ソースコードの分散の値を元に平方和を求め,さらに平均平方や自由度を求めることでFを算出しF分布表と比較した.その際の計算結果を表にまとめたものを以下に示す.
| 要因 | 平方和 | 自由度 | 平均平方 | F |
|---|---|---|---|---|
| 群間 | 301.70443 | 2 | 150.85221 | 130957.36348 |
| 群内 | 34.55410 | 29997 | 0.00115 | |
| 全体 | 297.8766 | 29999 |
計算結果より,群間の自由度が2,群内の自由度が29997なので1%有意水準のF分布表からF=4.61であるからF=130957.36348は棄却域に入った.したがって,帰無仮説は棄却され,3つのソースコードの処理速度の少なくとも1つの組み合わせに差があることが証明された.
検証結果から処理速度に差があるのは1つだけ平均が高いpd.Series.value_counts()のソースコードであるのは容易に考えられる.よって,pd.Series.value_counts()のソースコードは残りの2つのソースコードより処理速度の観点では劣っていると考えられる.
一方で残りの2つのソースコードの優劣については不明なのでこの2つのソースコードにおいて処理速度に差があるか調べるためt検定を行った.帰無仮説と対立仮説は以下の通りである.
次に各ソースコードの統計量値を元に不偏分散を求め,さらに標本平均の差や自由度を求めることでtを算出しt分布表と比較した.その際の計算結果を表にまとめたものを以下に示す.
| 要因 | 標本平均の差 | 差の標本標準誤差 | t |
|---|---|---|---|
| 0.00036 | 0.00057 | 0.63471 |
計算結果と自由度が9998より5%有意水準のt分布表からt=1.645なのでt=0.63471は棄却域に入っていない.したがって,帰無仮説は採択され,2つのソースコードの処理速度に差がないことが証明された.
検証結果から処理速度に差があるのは1つだけ平均が高いpd.Series.value_counts()のソースコードであるのは容易に考えられる.よって,pd.Series.value_counts()のソースコードは残りの2つのソースコードより処理速度の観点では劣っていると考えられる.
つまりこの検証から,groupby().size()とpd.DataFrame.value_counts()のソースコードの処理速度は同程度であるのに対して,pd.Series.value_counts()の方がより処理速度が遅いと考えられる.
2.4.2 2.3.2の検証結果の考察
2.3.2の検証結果から2×10000のデータに対して連続値のカウントを行うソースコードのメモリ使用量を代表値として分散分析,t検定を行うことで各ソースコードの比較,考察を行った.
まず,初めに3つのソースコードのメモリ使用量に差があるかを確認するため分散分析を行った.帰無仮説と対立仮説は以下の通りである.
次に各ソースコードの分散の値を元に平方和を求め,さらに平均平方や自由度を求めることでFを算出しF分布表と比較した.その際の計算結果を表にまとめたものを以下に示す.
| 要因 | 平方和 | 自由度 | 平均平方 | F |
|---|---|---|---|---|
| 群間 | 78.92267 | 2 | 39.46133 | 594.86126 |
| 群内 | 1.7911 | 27 | 0.06634 | |
| 全体 | 83.31172 | 29 |
計算結果より,群間の自由度が2,群内の自由度が27なので1%有意水準のF分布表からF=5.39であるからF=594.86126は棄却域に入った.したがって,帰無仮説は棄却され,3つのソースコードのメモリ使用量の少なくとも1つの組み合わせに差があることが証明された.
検証結果からメモリ使用量に差があるのは1つだけ平均が高いpd.Series.value_counts()のソースコードであるのは容易に考えられる.よって,pd.Series.value_counts()のソースコードは残りの2つのソースコードよりメモリ使用量の観点では劣っていると考えられる.
一方で残りの2つのソースコードの優劣については不明なのでこの2つのソースコードにおいてメモリ使用量に差があるか調べるためt検定を行った.帰無仮説と対立仮説は以下の通りである.
次に各ソースコードの統計量値を元に不偏分散を求め,さらに標本平均の差や自由度を求めることでtを算出しt分布表と比較した.その際の計算結果を表にまとめたものを以下に示す.
| 要因 | 標本平均の差 | 差の標本標準誤差 | t |
|---|---|---|---|
| 0.08000 | 0.096097 | 0.83250 |
計算結果と自由度が18より5%有意水準のt分布表からt=2.101なのでt=0.83250は棄却域に入っていない.したがって,帰無仮説は採択され,2つのソースコードのメモリ使用量に差がないことが証明された.
検証結果からメモリ使用量に差があるのは1つだけ平均が高いpd.Series.value_counts()のソースコードであるのは容易に考えられる.よって,pd.Series.value_counts()のソースコードは残りの2つのソースコードよりメモリ使用量の観点では劣っていると考えられる.
つまりこの検定から,groupby().size()とpd.DataFrame.value_counts()のソースコードのメモリ使用量は同程度であるのに対して,pd.Series.value_counts()の方がより多くのメモリを消費すると考えられる.
2.4.3 検定結果を踏まえた考察
2.4.1と2.4.2の考察で処理速度とメモリ使用量においてpd.Series.value_counts()のソースコードが他の2つのソースコードに劣っていることが分かった.その理由として繰り返しの処理であるリスト内表記のfor文が使われている点とキャストや文字列の追加等の処理が連続して行われている点の2つが考えられる.for文を用いて各行にアクセスすればその回数分メモリを多く使用し,処理速度も遅くなるのは自明である.
一方で残りの2つのソースコード,groupby().size()とpd.DataFrame.value_counts()の間では処理速度とメモリ使用量において差はなかった.その理由として双方のソースコードの実装に使われているOSSのコードが類似している,もしくは同じものが使われている可能性が考えられる.
実際にpandasの実装部分のソースコードを調べたところ両ライブラリの関数は以下のように定義されていた.
# groupby().size() def size(self) -> FrameOrSeriesUnion: result = self.grouper.size() # GH28330 preserve subclassed Series/DataFrames through calls if issubclass(self.obj._constructor, Series): result = self._obj_1d_constructor(result, name=self.obj.name) else: result = self._obj_1d_constructor(result) if not self.as_index: result = result.rename("size").reset_index() return self._reindex_output(result, fill_value=0)
# pd.DataFrame.value_counts() def value_counts( self, subset: Optional[Sequence[Label]] = None, normalize: bool = False, sort: bool = True, ascending: bool = False, ): if subset is None: subset = self.columns.tolist() counts = self.groupby(subset).grouper.size() if sort: counts = counts.sort_values(ascending=ascending) if normalize: counts /= counts.sum() # Force MultiIndex for single column if len(subset) == 1: counts.index = MultiIndex.from_arrays( [counts.index], names=[counts.index.name] ) return counts
上記の2つのソースコードを見比べてみると関数の引数の違いから多少の違いがあることでデータのソートや正規化の処理の差があるものの,groupby().size()はresult = self.grouper.size(),pd.DataFrame.value_counts()はcounts = self.groupby(subset).grouper.size()によって複数列の組み合わせのカウントを行っており,groupby().size()は事前にgroupby()の処理を行っているのでsize関数にgroupby()が記されていないが,どちらも同じ処理を行っているのである.
つまり,ソースコード上ではgroupby().size()とpd.DataFrame.value_counts()と違いがあるものの内部での処理が同じであるため処理速度やメモリ使用量に大きな違いが生まれず,結果として検定を行っても差がなかったのだと考えられる.
2.5 結論
pandasにおける複数列の組み合わせのカウントを行う
cols = ["group", "value"] tmp_df = df[cols].astype(str)\ .apply(lambda lis: [ x for x in lis], axis=1)\ .str.join(" | ")\ .value_counts()
上記のソースコードより以下の2つのpandasにおける複数列の組み合わせのカウントを行う
tmp_df = df.groupby(['group','value']).size().reset_index()
tmp_df = df.value_counts().reset_index()
この後者の2つのソースコードの方が処理速度,メモリ使用量の点において優れている.
しかしこの後者の2つのソースコードの間に処理速度,メモリ使用量の点において優劣は存在しなかった.
また,groupby().size()とpd.DataFrame.value_counts()の内部の複数列の組み合わせのカウントを行う処理は同じであった.
2.6 文献
- pandasにおける複数列の組み合わせのカウント(pd.Series.value_counts())
- pandasにおける複数列の組み合わせのカウント(groupby().size())
- t分布表とF分布表
http://ktsc.cafe.coocan.jp/distributiontable.pdf